I. Motivation: Applications
Speech recognition is a fascinating application of digital signal processing (DSP) that has many real-world applications. Speech recognition can be used to automate many tasks that previously required hands-on human interaction, such as recognizing simple spoken commands to perform something like turning on lights or shutting a door. To increase recognition rate, techniques such as neural networks, dynamic time warping, and hidden Markov models have been used. Recent technological advances have made recognition of more complex speech patterns possible. For example, there are fairly accurate speech recognition software products on the market that take speech at normal conversational pace and convert it to text so no typing is needed to create a document. Despite these breakthroughs, however, current efforts are still far away from a 100% recognition of natural human speech. Much more research and development in this area are needed before DSP even comes close to achieving the speech recognition ability of a human being. Therefore, we consider this a challenging and worthwhile project that can be rewarding in many ways.
Recognizing natural speech is a challenging task. Human
speech is parameterized over many variables such as amplitude, pitch, and
phonetic emphasis that
vary from speaker to speaker. The
problem becomes easier, however, when we look at certain subsets
of human speech. For instance, vowels and consonants in the English
language are produced in different ways by the vocal tract and accordingly
possess unique features that can be exploited to differentiate them from each other. The group,
Digital Bubble Bath, from the class of 1996 utilized Formant analysis to
isolate, characterize, and identify vowels by their resonant frequencies
with great success. Digital Bubble Bath focused on the periodic steady
state characteristics of speech. Our group aimes to identify speech by its
transient characteristics which include recognition of consonants. We
chose the spoken digits one to five as our study set since they are short
monosyllabic words with a detectable amount transient behavior. The time domain representation of a spoken five is shown in Figure 2.1.
A sample set of all five spoken digits may be found here.
Just looking at the time domain signals is not going to cut it. We want to
look at as few things as possible to make our comparisons, and the time
signals, although appear different to the human eye, require the integration
too many details to come up with a succinct criterion of discernment.
One possibile solution is to take the signal into the frequency domain via
the Fourier Transform to
determine if there are any salient frequencies that may distinguish one digit
from another. The Fourier Transform, however, projects signals onto
complex sines and cosines - infinitely long signals. That we are dealing
with transient characteristics - very short signals - hints that Fourier
basis may not be the best choice for analysis. In fact because transient signals
are localized in time, they are very rich in spectral
content. Many Fourier components are required to synthesize temporally
localized signals. We want pithy comparisons not longwinded ones -
otherwise we might as well be better off comparing the time domain
representations. Clearly we need a basis that matches the transient signal
better - one that carries both temporal location - like an impulse - and
frequency content - like a sinusoid.
It turns out that there do exist basis functions that fit the bill - namely
wavelets. Wavelets are a cross between the impulse and the sinusoid - a
wiggle that's localized in time. The wavelet dies off at negative and
positive infinity giving location in time. The wavelet's wiggle gives the
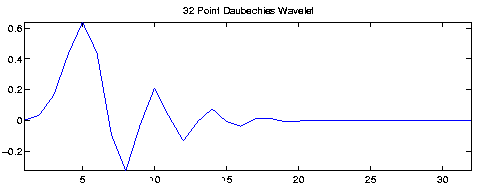
frequency content. For our project we chose the 32 point Daubechies
wavelet generated by the Matlab command daubcqf.m from the
Rice Wavelet Toolbox for
MATLAB for two reasons.
The 32 point
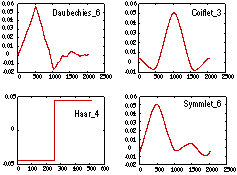
Daubechies wavelet is shown in Figure 4.2. A few other wavelets are shown
below in Figure 4.3 as well.
With Fourier Analysis we compared our signals to a basis consisting of sinusoids
that differed in frequency. With wavelet analysis we compare our signals
to a basis consisting of wiggles that differ in frequency and temporal location.
Surprisingly such a set is generated by one wavelet prototype or mother
wavelet. The wavelet W
may be represented through the wave equation as a function of two parameters - frequency and time and
thus may be expressed as:
where t is time, f is frequency and t' is the time delay. Varying the two
parameters of the wavelet has physical consequences. We use the mother
wavelet X shown in Figure 4.4 to demonstrate these changes.
By varying f we can compress and dialate the prototype wavelet to obtain wavelets of
higher frequency and wavelets of lower frequency respectively - much
like varying the frequency w in a sine function - sin(wt). Figure 4.5
shows the result of multiplying the f of X by a factor of 0.5
By varying
t' we can translate the wavelet in time. Figure 4.6 shows the result of
subtracting some delay in the argument of X.
By varying both parameters we can generate a wide domain of wavelets
each representing a different frequency content within different time
intervals.
Once a set of wavelets is generated from the prototype wavelet, the signal
is projected onto the set via the dot product - or in more formal
terminology the wavelet transform. If the two parameters f and t' are
stepped through continuously we have the continuous wavelet transform. On
the other hand if the two parameters are stepped through discretely we have
the discrete wavelet transform. For our project, we chose the discrete
wavelet transform (DWT) using the Matlab function mdwt.mexsol from the
Rice Wavelet Toolbox for MATLAB. The DWT steps through frequency and time by factors
of two. Hence the DWT projects the signal onto a set of octaves - wavelets
that differ in frequency by factors of two. The majority of our working
recognition algorithm relied on differentiating digits by their octaves.
II. Problem Definition: Digit Recognition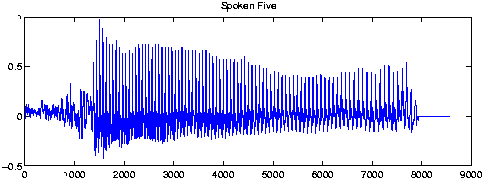
III. The Approach: Time Frequency Analysis
IV. The Right Tools: Daubechies Wavelet Basis
![]()