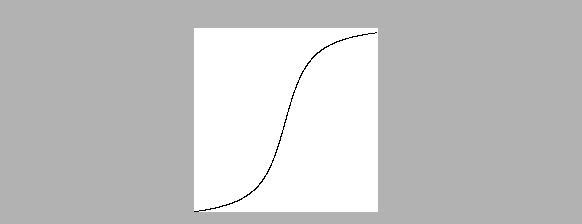
Images are typically coded with a maximum of 8 bits. Due to the energy compaction offered by the DCT, the big coefficients are really big and will take more than 8 bits to code. If we look at the raw transform, the largest values are typically in the +/- 20,000 range. That would take 16 bits to encode! What we need to do is to scale down the values so that we can encode them using 8 bits, i.e. values from 0 to 256. But since we have to account for the negative values also, we really only have values in the range of -128 to 127. We cannot just divide the whole transformed image by some number to get that range because we would lose too much information. Too many of the small coefficients would be set to zero. What we need is some sort of a non-linear scale that would bring the extremely high values down while doing relatively little to the small values. In other words, we need to multiply the image by something that looks like this:
An arctan function or a log function would give us exactly what we want. It has a linear scale close to the center and would cap off the really large values. We decided to use the log (base e) function.
This is our basic algorithm for encoding our images:
To decode, we read in our binary file and our mask. The number in the mask corresponds to the number of bits each block was coded in.
By shifting the original image, we also shift the DCT. We do this so that the DCT's magnitude of the lowest and highest values would be at least in the range of the same magnitude, thus allowing us maximum utilization of our -128 to 127 range. The scaling of the values allows us to merely round the DCT instead of doing a complicated quantization. By scaling the DCT, we guarantee that we have 28 values.
Our mask is created by looking at some sample DCT's. It is purely ad hoc. Furthermore, we found that the "niceness" of the images corresponded more to how the mask is made rather than to PSNR or to MSE. We were able to code a way to adaptively figure out what the mask needed to be to get lossless compression but that involved sending too much overhead in our binary file.