
Our OCR system works by converting a page of scanned text into the actual characters. The first step of this process is segmentation. Segmentation works by dividing the image into many distinct images, each surrounding an object in the total image. A variety of edge detection methods including gradients and zero-crossings were looked into, but most were overkill for our application. Since the scanned image is primarily a simple 1-bit black and white image, simpler and faster techniques can be used.
The final segmenter of this project is very simple, but works very effectively and very fast. A normal 900x900 scanned image takes approximately 1.8 seconds to segment on a 70MHz SPARC. Basically, the algorithm works as follows: It loops through all pixels of the image, looking for a drawn pixel. When it finds one, it then attempts to find the edges of the object containing that point. A simple function starts at the pixel, and expands each edge point (left, right, top, bottom) until that edge is beyond the object. When all the edges are beyond the object, it has been enclosed. The object is erased from the total image and the algorithm continues scanning for objects.
Several optimizations were added to make the algorithm more robust and useful. First, when enclosing an object, the algorithm has a lookahead width that it uses to make sure the object does not just have a temporary discontinuity. This helped with degraded or poorly scanned images. Second, a minimum object area is specifiable which allows for the elimination of stray noise pixels that would show up as objects. Finally, the algorithm determines which objects are in the same "row" so that the resulting objects are in the correct "human readable" left->right top->bottom order. Before this, if one object was slightly higher than another, it would be listed first even if it was to the right of the other object. This ordered list was implemented as a linked list where objects were sorted on insertion.
The segmenter was originally coded in matlab, but due to the dependence on loops and conditionals, it was quickly converted to C for speed. Here is the source code
Figure 1 shows a sample scanned image of various symbols. The segmenter was run on these images, and the computed edges were used to drop boxes around the objects. The surrounding box is the minimal size box that completely encloses the object. Figure 2 shows these same symbols extracted into individual objects. These individual objects would then be sent to the image feature extraction and classification systems.
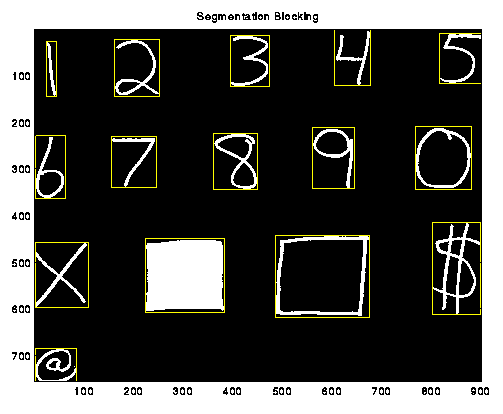
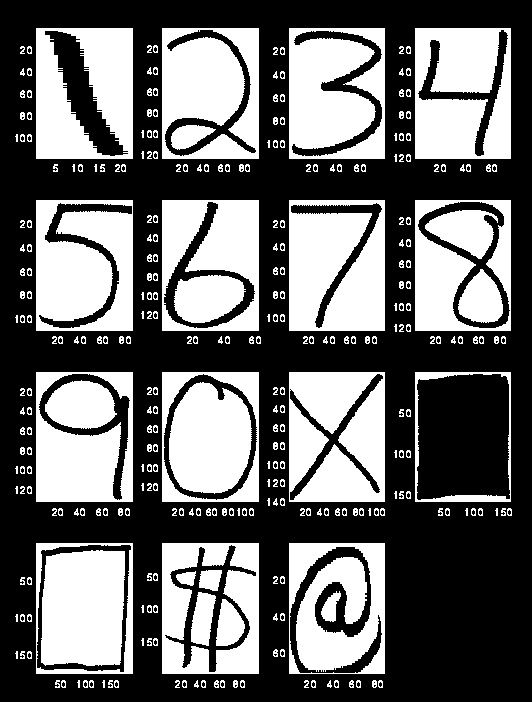
As these images show, our segmenter works very well. Only one circumstance will confuse it. If two symbols are drawn in such a way that their distinct boxes overlap, they will be considered a single object. This should not happen for most well-formed objects. (Cursive doesn't count)