Introduction
As a classifier we decided to use Artificial Neural Net (ANN).
Handwritten digit recognition is a complex problem due to many
variations in the patterns to be classified. ANN's have been
previously successfully applied to handwritten digit recognition.Those
approaches were very involved and recognized size normalized images of
digits. Instead we decided to classify feature vectors generated by
methods described in previous section. ANN was chosen as a classifier
because once it has been trained, the classification is done very
efficiently.
Description of Work
ANN can be used a supervised classifier or as an unsupervised one.
During supervised classification each input vector is assigned to a
specific target class. During the training process ANN adjusts its
weights as to minimize the sum squared error calculated from the
actual o/p and the desired one. This error is used to adjust weights
so that during the next pass error would be smaller.
During unsupervised classification ANN tries to learn
correlations in the input vectors and adapt the weights so that the
network response is similar to the input vectors belonging to the same
class.
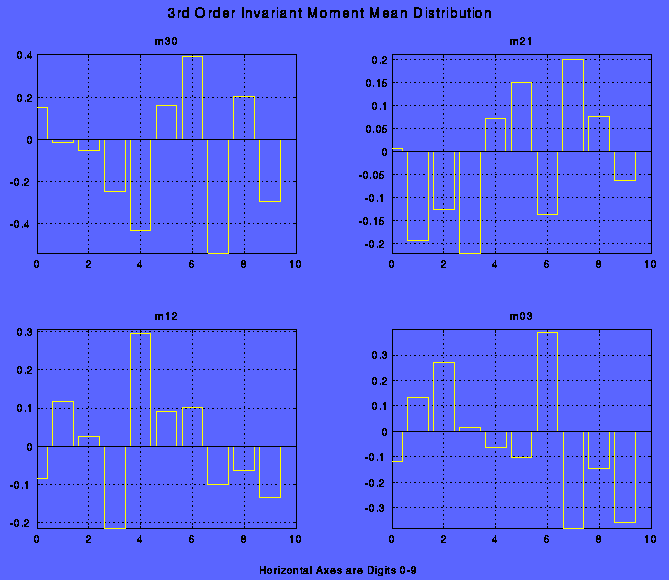
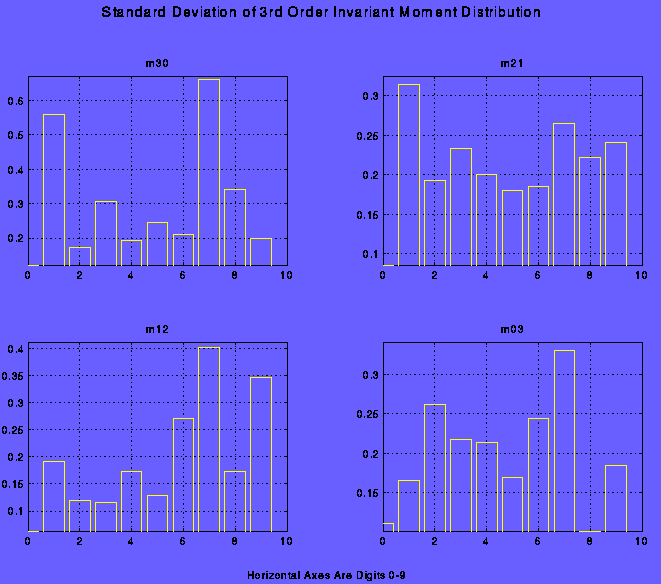
We tried both approaches and found that supervised classification yielded better results. Once the training method was defined, we tried two methods of classification. The first method consisted of training a net with all of the calculated features at once. Features used were moments (3rd to 6th order), circularity, number of holes and y median values. Desired output was 10 classes. This approach worked well with perfect times font digits, free from noise. Handwritten digits could be considered as a noisy versions of a typeset ones. Accordingly ANN was trained initially with a features of a typeset characters and then with a features of handwritten digits. This approach proved to be an exercise in futility due to the two reasons. First, handwritten digits are not at all similar to the typeset ones, variation is great. Second, there is a very large overlap between many features, consequently not all of them can be used for classification. As an example, please see the graph showing the large standard deviation of the third order moments.
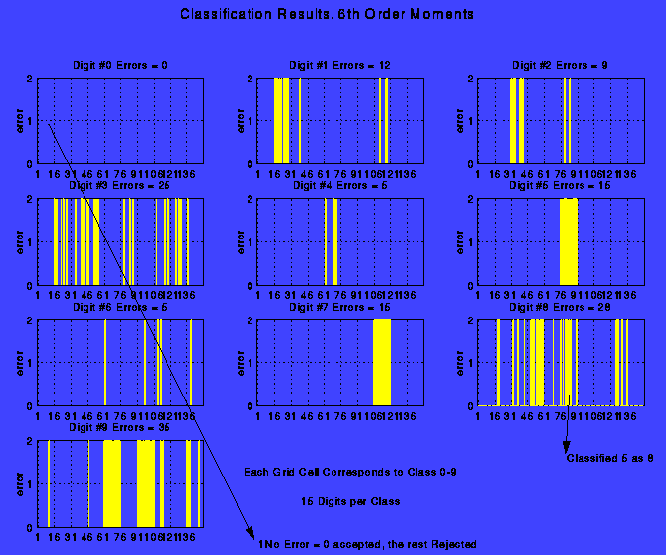
| Digit 0 | All Sixth Order Moments |
| Digit 1 | m30; m21; m40; m04; m31; m13; m12; m03; m50; m41; m14; hole number |
| Digit 2 | m21 m12 m30; All 4th Order Moments |
| Digit 3 | m21 m12 m30; All 4th Order Moments and Hole Count |
| Digit 4 | All 4th Order Moments |
| Digit 5 | m30; m21; m40; m04; m31; m13; m12; m03; m50; m41; m14; hole number |
| Digit 6 | m21 m12 m30; All 4th Order Moments |
| Digit 7 | 3rd, 4th, 5th, 6th order moments |
| Digit 8 | m30; m21; m40; m04; m31; m13; m12; m03; m50; m41; m14; hole number |
| Digit 9 | 3rd, 4th, 5th, 6th order moments |
The end-product was a classifier consisting of 10 neural nets similar to the one shown below.

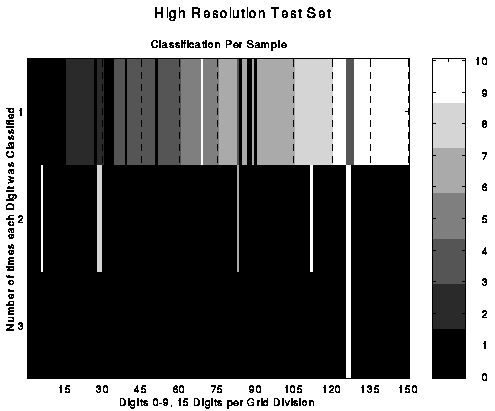
Big Answer would be the one our classifier comes up when unknown input is presented. As it stands right now, each of our 10 classifiers gives an answer, optimally only one of them would be a positive, meaning that digit was identified, optimum was not always a case and sometimes we got more than a one answer as can be seen in the graph below.