Progress Report 4: 12/14/1996
Well, now we know that we do well with black-and-white images, but how do we do
with something more complicated? For example, let's try a word...
[Note that this is a totally random bit of text..... ;-) ]
>> [letters,map1]=gifread('bigtext2.gif');
>> colormap(map1);
>> image(letters)

We start by trying to find one of the words.
>> template=letters(63:98,186:280);
>> colormap(map1);
>> image(template)
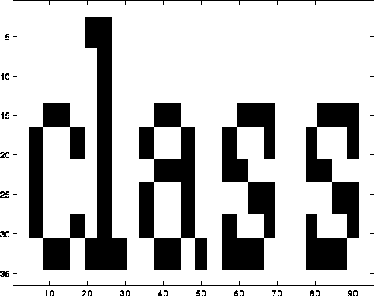
Picture Adjustment
>> letters=letters-1;
>> template=template-1;
Due to the flipping effect that we noticed with the last picture (pisces), we
decided to use 2-D correlation as the references suggested. In Matlab, this
is the cross-correlation function, xcorr2, and it is used the same way in our
programs.
Straight 2-D correlation: normalization numerator.
>> correlate_2D = xcorr2(letters,template);
>> colormap(gray(max(max(correlate_2D))));
>> image(correlate_2D);
Denominator calculation.
>> letterssqr=letters.^2;
>> flat=ones(size(template));
>> norml = xcorr2(letterssqr,flat);
>> rtnorml = norml .^ 0.5;
>> colormap(gray(max(max(rtnorml))));
>> image(rtnorml);
Remove problem with division by zero.
>> rtnorml = rtnorml + .1;
>> cnvnorm = correlate_2D ./ rtnorml;
>> colormap(gray(max(max(cnvnorm))));
>> image(cnvnorm);
That's pretty hard to tell. We use thresholding to isolate our image.
>> [a,b]=size(cnvnorm);
>> most=max(max(max(cnvnorm)));
>> for rows=1:a
for cols=1:b
if (cnvnorm(rows,cols)<(most)) cnvnorm(rows,cols)=0;
end
end
end
>> colormap(gray(2));
>> image(cnvnorm);
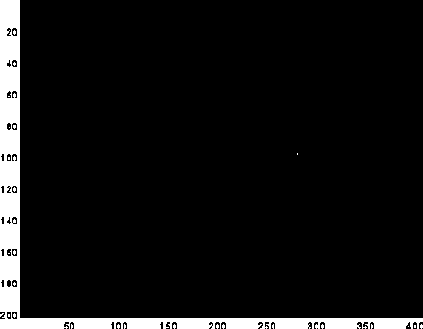
We notice that the result of the convolution/correlation is larger than the original
image. This is not a problem, except that it isn't obvious that the code is finding
the right image.
The convolution result is of size (x-template+x-image)-1 by (y-template+y-image)-1.
We need to cut out the first (xtemplate-1) pixels in the x as they are meaningless.
The same holds true for the y axis. We add some code to accomplish this.
>> [a,b]=size(cnvnorm);
>> [x,y]=size(template);
>> save=cnvnorm(x:a,y:b);
>> colormap(gray(2))
>> image(save);
This pinpoints the upper left-hand corner of the template in the image.
We extracted letters(63:98,186:280). There is just one non-zero point in the final
matrix. Where is it?
>> [a,b]=size(save);
>> for i=1:a
for j=1:b
if save(i,j)~=0 final=[i j];
end
end
end
>> final
final =
63 186
So, we did find the word! Cool!
Well, let's go smaller and see if we can find one particular letter. We choose to test for 's' because there are several of them.
>> [letters,map1]=gifread('bigtext2.gif');
>> colormap(map1);
>> image(letters)
We need the template to match.
>> template=letters(76:96,143:156);
>> colormap(map1);
>> image(template)
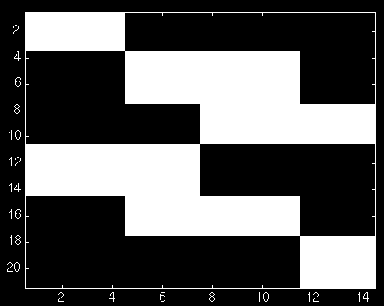
Picture Adjustment
>> letters=letters-1;
>> template=template-1;
Straight 2-D correlation: normalization numerator.
>> correlate_2D = xcorr2(letters,template);
>> colormap(gray(max(max(correlate_2D))));
>> image(correlate_2D);

Denominator calculation.
>> letterssqr=letters.^2;
>> flat=ones(size(template));
>> norml = xcorr2(letterssqr,flat);
>> rtnorml = norml .^ 0.5;
>> colormap(gray(max(max(rtnorml))));
>> image(rtnorml);
Remove problem with division by zero.
>> rtnorml = rtnorml + .1;
>> cnvnorm = correlate_2D ./ rtnorml;
>> colormap(gray(max(max(cnvnorm))));
>> image(cnvnorm);
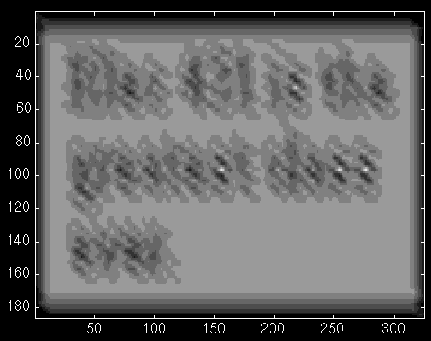
That's pretty hard to tell. We use thresholding to isolate our image.
>> [a,b]=size(cnvnorm);
>> most=max(max(max(cnvnorm)));
>> for rows=1:a
for cols=1:b
if (cnvnorm(rows,cols)<(most)) cnvnorm(rows,cols)=0;
end
end
end
>> colormap(gray(2));
>> image(cnvnorm);
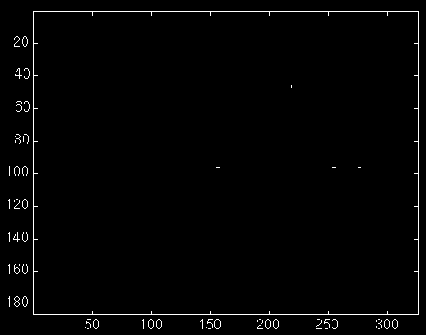
Resizing.
>> [a,b]=size(cnvnorm);
>> [x,y]=size(template);
>> save=cnvnorm(x:a,y:b);
>> colormap(gray(2))
>> image(save);
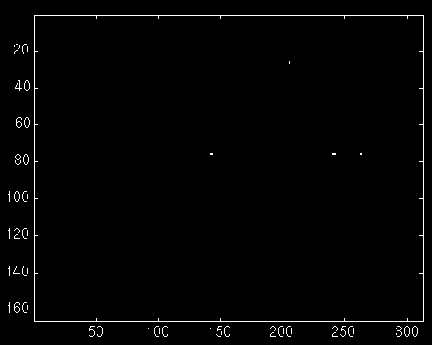
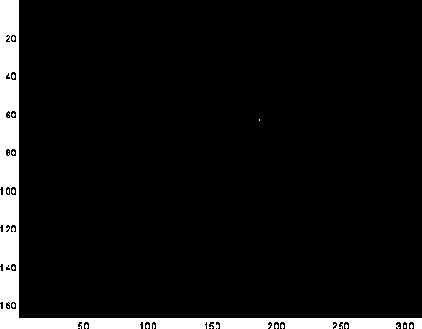
This pinpoints the upper left-hand corners of the templates in the image.
We extracted letters(76:96,143:156). There are four spots of non-zero points in
the final matrix. Where are they?
>> final=[];
>> [a,b]=size(save);
>> for i=1:a
for j=1:b
if save(i,j)~=0 final=[final;i j];
end
end
end
>> final
final =
26 205
27 205
76 142
76 143
76 144
76 240
76 241
76 242
76 262
76 263
The images are not distinct dots, but basically there are four spots:
(27,205), (76,143), (76,242) and (76,263). That' four, and that means we found
all the instances of the letter "s"! Even cooler!