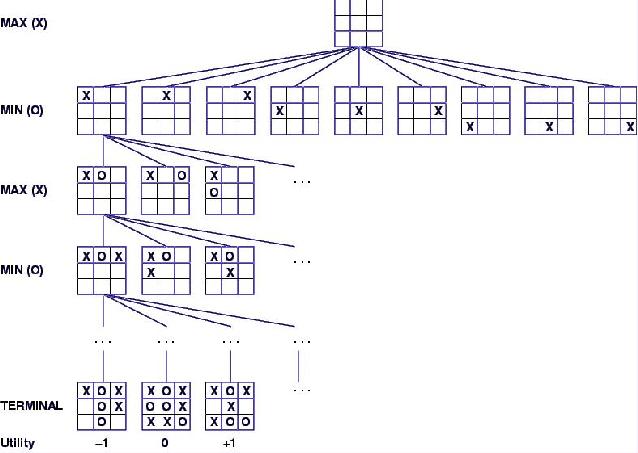
Figure 1. An example of simple minimax algorithm on the game of tic-tac-toe.
Static Board Evaluation, Minimax, Alpha-Beta Pruning
You don't need this lab to do the Connect Five project. You don't even have to use it for the extra credit. It talks about an improved way of extending a static valuation function to a search-ahead method, by pruning off parts of the search when you can tell they're not better than some other part of the your search.
If you are simply given a board position, how can you figure out what move is best? The basic approach is to assume that you can give a numeric value to any board position. E.g., if the game is over and you have won, it should receive the best possible value, let's say +1.0. If the game is over and you have lost, it should receive the lowest possible value, let's say -1.0. A draw would be in the middle, or 0.
Can you come up with a way to assign a value for other board positions, when the game isn't done yet? This is the hard part.
One basic approach is to come up with some heuristics based on game strategy. E.g., for Connect 5, I might look at the number of 4-in-a-rows, 3-in-a-rows, and 2-in-a-rows I have and somehow add them up, and subtract the 4-in-a-rows, 3-in-a-rows, and 2-in-a-rows my opponent has, weighting the 4-in-a-rows most heavily. This valuing isn't necessarily 100% accurate, but it's easy to do. In my code, I would write a function that finds a move that maximizes the value. (I don't necessarily need a function that computes the value of the current board. Think about why this is the case.) This should find any immediately winning move, and do a reasonable job otherwise.
Another basic approach just extends the previous one to look ahead several moves. In order to find out what move to make, I'll see what would happen if I made each of the possible moves. After I make a move, my opponent gets to move. After that, I can make a move, then my opponent, etc., until the game ends. This makes a (large) tree of game positions, with the children of a game position being all those obtained after a possible move.
Figure 1. An example of simple minimax algorithm on the
game of tic-tac-toe.
I can easily assign values to these final won, lost, or drawn positions. Working backwards, I want to assign values to earlier positions, based on what happens later. If I'm forced to lose a move later, that's as bad as having lost. Along the way, I should always pick my best move, i.e., the one with the maximum value, whenever it is my turn. I should also assume that my opponent is just as smart and picking his/her best move, i.e., the one with the minimal value, whenever it is his/her turn.
The minimax algorithm describes perfect play for deterministic, perfect-information games. The goal of the algorithm is to achieve the best payoff against best play.
Minimax Properties:
Minimax Algorithm:
Minimax(state, my-turn?)
(final? state), return a valuation of the
board (one of {WIN, LOSS, DRAW})
(lambda (a-next-state) (minimax a-next-state (not my-turn?)))
onto (successors-of state)
(maximum {results}) with corresponding moves.
(minimum {results}) with corresponding moves.
Thinking ahead for the rest of the game is impractical except for very simple games (like tic-tac-toe). This is because there can be a very large number of moves and board positions. In practice, I can only think ahead a few moves. This still generates a tree of moves and board positions, but one where the leaves are not necessarily finished games. Instead, I need to use my heuristic board evaluation routine to estimate the values of these positions.
Modified Minimax Algorithm:
Minimax(state, depth, turn)
(zero? depth) then return
(static-board-evaluation state)
(lambda (a-next-state) (minimax a-next-state (sub1 depth) (not my-turn?)))
onto (successors-of state)
(maximum {results}) with corresponding moves.
(minimum {results}) with corresponding moves.
You'll have a hard time searching more than 2 moves ahead in the time alotted. Compare to the 8+ moves that good human chess players look ahead or the 14+ moves that good chess programs look ahead.
All this said, a good valuation function can make or break your searching. For instance, the 2001-fall Connect5 tournament winner did no searching -- her program took < 2 seconds per move.
We can improve on the performance of the minimax algorithm through the use of alpha-beta pruning. The idea is that we can prevent ourselves from exploring branches of the game tree that are not worth exploring (because they will have no effect on the final outcome. Consider the following situation:
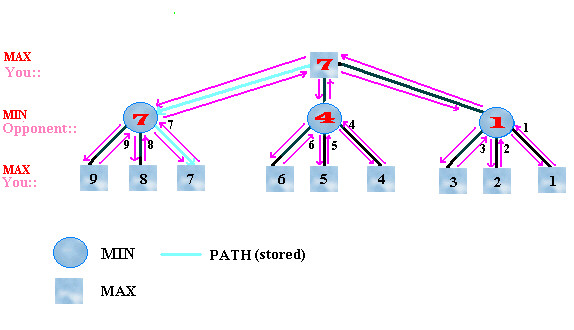
Figure 2. An example where alpha-beta pruning would help
in the minimax algorithm.
The minimax algorithm provides us with the optimal path as expected. But did we really need to do all that work? In particular, look at nodes 5 and 4. Let's pretend that we are at the middle level stage of finding the minimum value between nodes 6, 5, and 4. We have already calculated the value of node 6. So, we are at least guaranteed that the minimum value between these 3 nodes is ≤ 6.
But wait! On the level above (top level), we are trying to maximize the values. We've already calculated a value of 7 to the left. Something that is guaranteed to be 6 or less will never be greater than 7, so why go any further with the calculations?
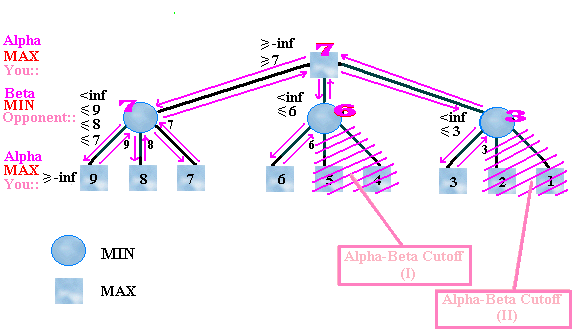
Figure 3. An example on adding alpha-beta pruning to the
minimax algorithm.
Mentally trace through the steps to convince yourself of this. The same property holds true for nodes 1 and 2.
Modified Minimax Algorithm with Alpha-Beta Pruning:
inputs: state - current state of game depth - number of lookaheads remaining my-turn? - whose turn it is (also indicates whether we maximize or minimize) alpha - the best score for max along the path to state beta - the best score for min along the path to state Minimax(state, depth, my-turn?, alpha, beta)
(Lookahead-Limit-Reached? depth) then return
(static-board-evaluation state)
if my-turn? (maximizing):
alpha = -infinity
for each s in {Successors state)
alpha = (maximum alpha (Minimax s (sub1 depth) (not my-turn?) alpha beta))
if (> alpha beta) return alpha
end
return alpha
if not my-turn? (minimizing):
beta = +infinity
for each s in {Successors state)
beta = (minimum beta (Minimax s (sub1 depth) (not my-turn?) alpha beta))
if (< beta alpha) return beta
end
return beta
The number one way to think of strategies: play the game by hand, with friends! (Or if you don't have any friends :-(, start the editor emacs, and start its built-in Connect 5 player by typing <ESC> x and entering gomoku.) You can both discuss why you are trying various moves, to see what does and doesn't work.
If you are going for the extra credit, be sure to first get a solid, working version of the program, before progessing on to making it better.
Making your board evaluator smarter generally makes it slower. You look for more kinds of patterns to make more interesting distinctions. Making your game tree search smarter generally means making it search more of the tree. You can try to make the search faster so that you can look another move ahead. Or you can try to figure out what parts of the tree you don't even need to look at ("pruning" the tree) and what order to search the tree in (to maximize pruning).
In the recent past, most of the better programs for this assignment haven't searched ahead at all. In the given time limits, your time is generally better spent on a good board evaluator.
Historical note: In the late 1980's, Hitech (from Carnegie Mellon University) was generally the computer chess program to beat. It was designed by a former world champion of postal chess, and his goal was to make the program as smart as possible, both in board evaluation and searching. A rival program, Deep Thought (also from CMU; the predecessor of Deep Blue from IBM) was started with an entirely different goal. Rather than being smart, Deep Thought was mainly fast so that it could look ahead more moves than any other program. As both programs improved, they traded top honors among all chess programs back and forth, with Deep Blue eventually the clear winner.